
|
About MeI am a year-3 master student at Tsinghua University, under the supervision of Prof. Xiu Li. I am fortunate to be collaborating closely with Dr. Lin Song on Vision Language Model. Before that, I obtained my BSc in Mathematics and Applied Mathematics at Xidian University in 2023. My research interest includes Multi-Modal Learning and Computer Vision. |




News[2026.04] We are excited to release the project, JoyAI-Image-Edit [2026.04] We are excited to release the project, SpatialEdit [2026.01] The paper LongLive and QeRL are accepted by ICLR 2026 (CCF-A) [2025.10] Obtain National Scholarship, Tsinghua University [2025.09] The paper MindOmni is accepted by NeurIPS 2025 (CCF-A) [2025.09] The Paper SOC++ is accepted by TPAMI 2025 (CCF-A) [2025.06] We are excited to release the project, MindOmni [2025.05] Two papers, LoRA-Gen and HaploVLM are accepted by ICML 2025 (CCF-A) [2024.10] Obtain National Scholarship, Tsinghua University [2024.06] Two papers, MambaTree (Spotlight) and COVE are accepted by NeurIPS 2025 (CCF-A) [2024.03] The paper UVCOM is accepted by CVPR 2024 (CCF-A) [2023.09] The paper SOC is accepted by NeurIPS 2023 (CCF-A) [2023.09] The first prize of The 5th Large-scale Video Object Segmentation Challenge Track3: Referring Video Object Segmentation [2023.03] The paper SemanticAC is accepted by ICASSP 2023 (CCF-B) [2021.12] Obtain National Scholarship, Xidian University |
Academic experience
|


Industrial experience
|



Honors and Awards[2025] National Scholarship for Master's Students, Tsinghua University [2024] National Scholarship for Master's Students, Tsinghua University [2022] National Scholarship for Undergraduate Students, Xidian University [2023] The First Prize of ICCV 2023 The 5th Large-scale Video Object Segmentation Challenge Track3: Referring Video Object Segmentation |

|
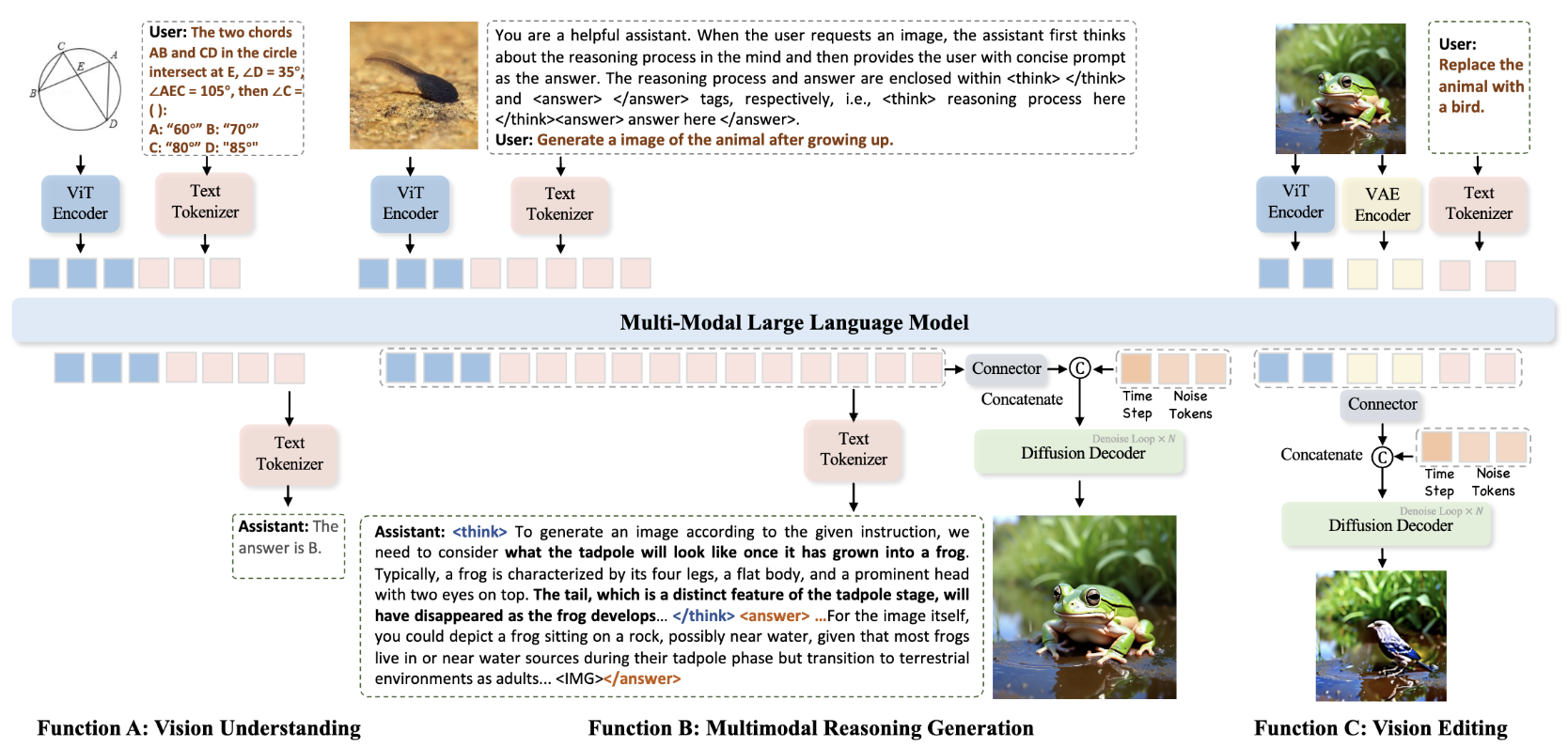
JoyAI-Image: Awakening Spatial Intelligence in Unified Multimodal Understanding and GenerationCore Contributor Technical Report / Paper / Code |

|
SpatialEdit: Benchmarking Fine-Grained Image Spatial EditingYicheng Xiao, Wenhu Zhang, Lin Song, Yukang Chen, Wenbo Li, Nan Jiang, Tianhe Ren, Haokun Lin, Wei Huang, Haoyang Huang, Xiu Li, Nan Duan, and Xiaojuan Qi Under Review / Paper / Code |
|
MindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPOYicheng Xiao, Lin Song, Yukang Chen, Yingmin Luo, Yuxin Chen, Yukang Gan, Wei Huang, Xiu Li, Xiaojuan Qi, Ying Shan NeurIPS 2025 / Paper / Code |
|
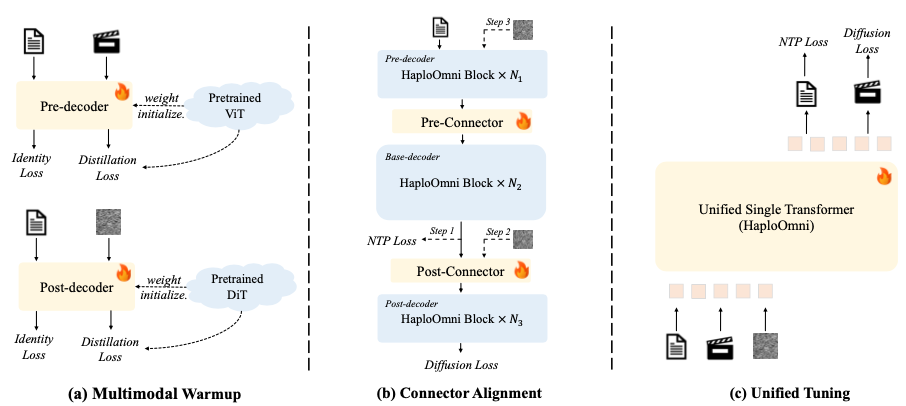
HaploOmni: Unified Single Transformer for Multimodal Video Understanding and GenerationYicheng Xiao*, Lin Song*, Rui Yang, Cheng Cheng, Zunnan Xu, Zhaoyang Zhang, Yixiao Ge, Xiu Li, Ying Shan (* equal contribution) Under Review / Paper / Code |
|
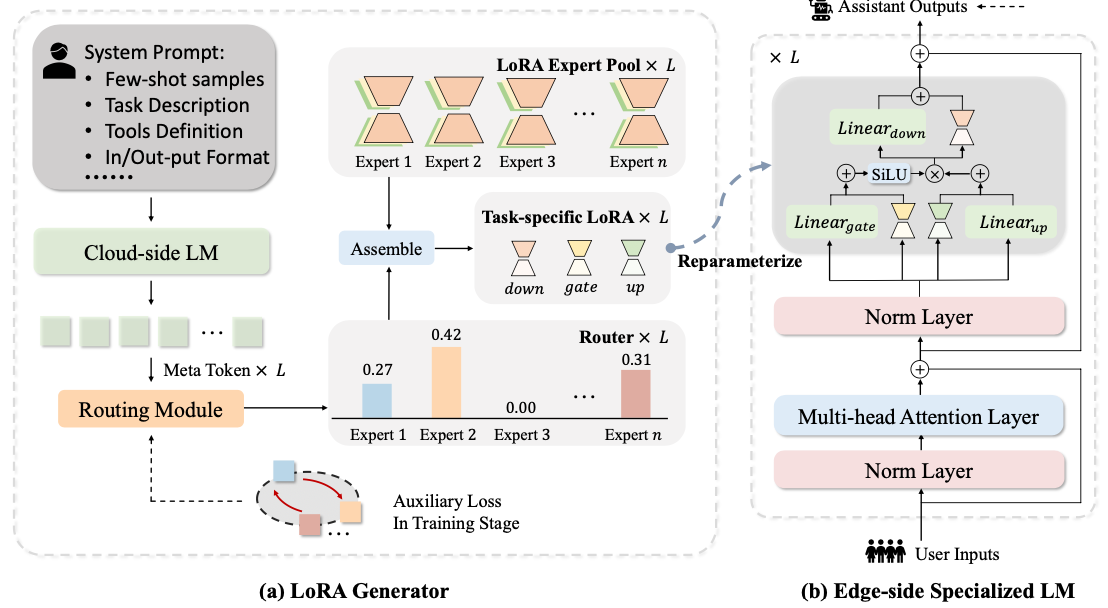
LoRA-Gen: Specializing Language Model via Online LoRA GenerationYicheng Xiao*, Lin Song*, Rui Yang, Cheng Cheng, Yixiao Ge, Xiu Li, Ying Shan (* equal contribution) ICML 2025 (CCF-A) / Paper / Code |
|
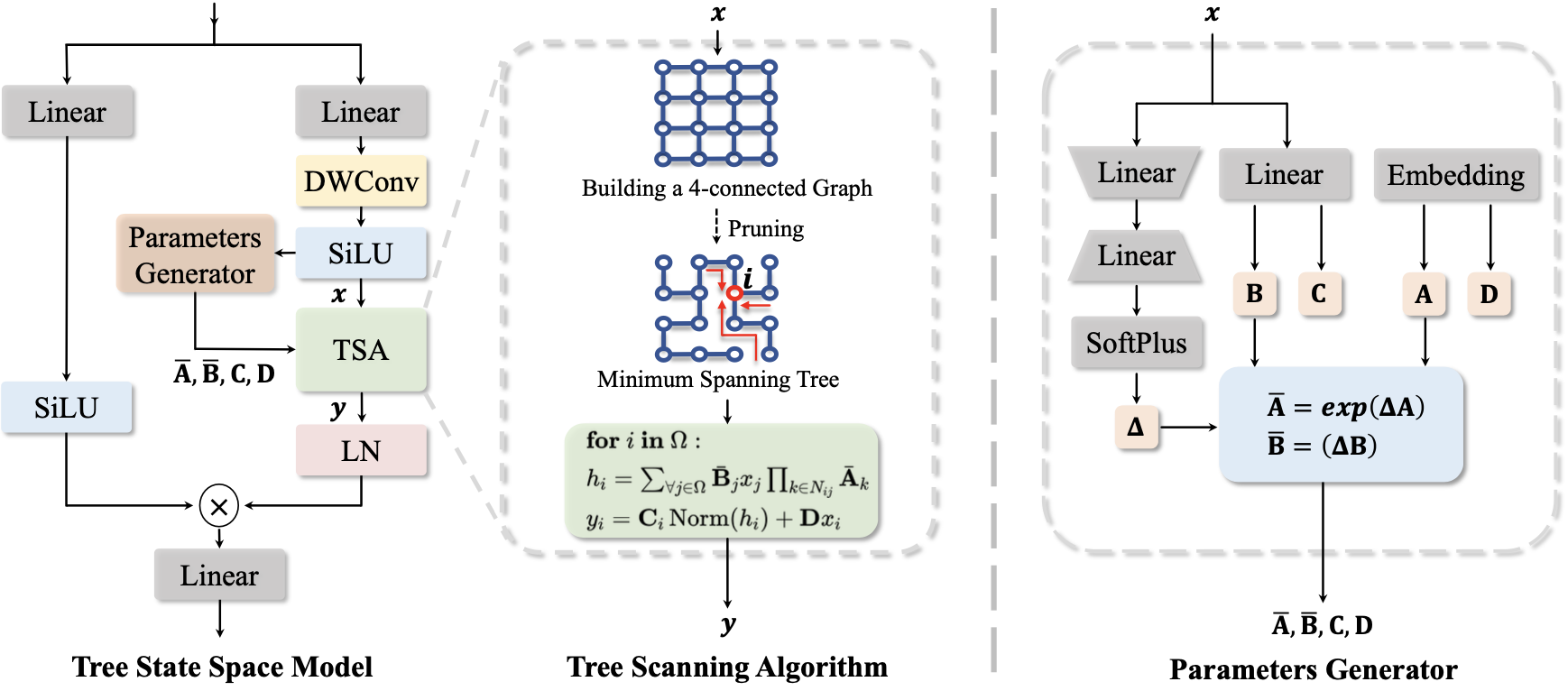
MambaTree: Tree Topology is All You Need in State Space ModelYicheng Xiao*, Lin Song*, Shaoli Huang, Jiangshan Wang, Siyu Song, Yixiao Ge, Xiu Li, Ying Shan (* equal contribution) NeurIPS 2024 Spotlight (CCF-A) / Paper / Code |
|
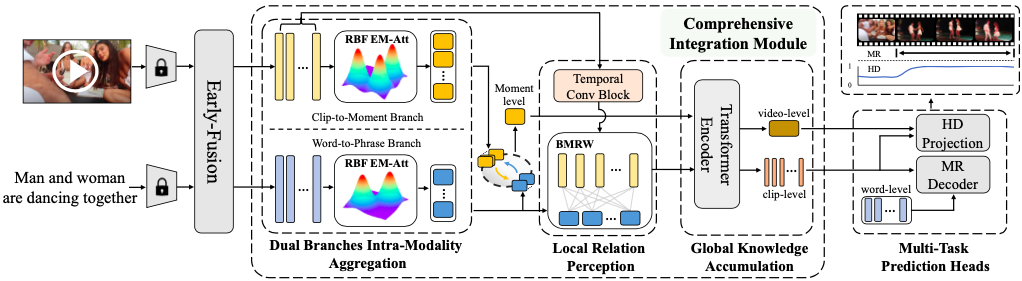
Bridging the Gap: A Unified Video Comprehension Framework for Moment Retrieval and Highlight DetectionYicheng Xiao*,Zhuoyan Luo*, Yong Liu, Yue Ma, Hengwei Bian, Yatai Ji, Yujiu Yang, Xiu Li (* equal contribution) CVPR 2024 (CCF-A) / Paper / Code |
|
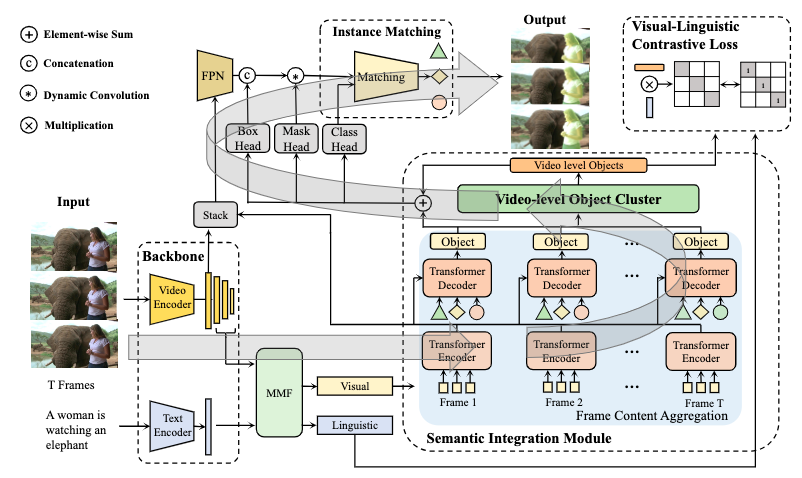
SOC: Semantic-Assisted Object Cluster for Referring Video Object SegmentationZhuoyan Luo*, Yicheng Xiao*, Yong Liu*, Shuyan Li, Yitong Wang, Yansong Tang, Xiu Li, Yujiu Yang (* equal contribution) NeurIPS 2023 (CCF-A) / Paper / Code |
|
Thanks Jon Barron for this template. |